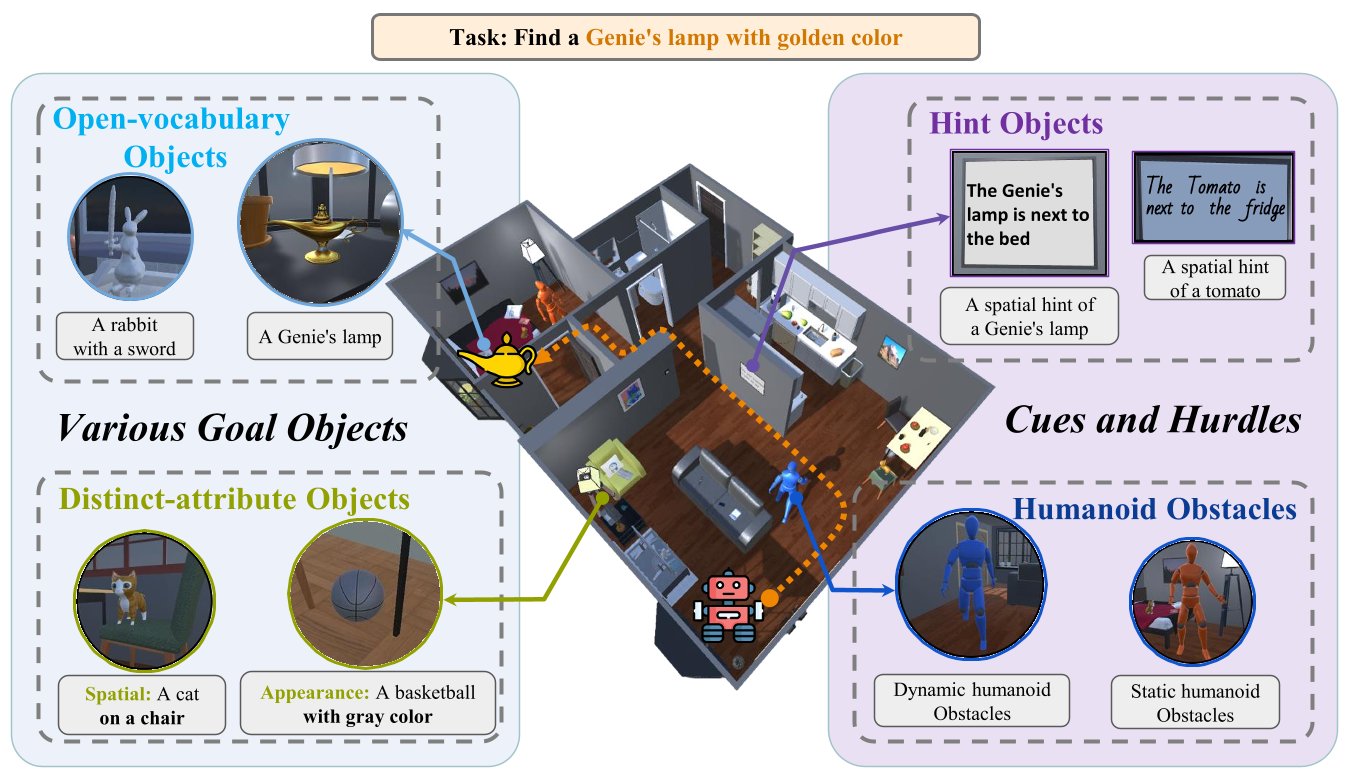
Abstract
Zero-Shot Object Navigation (ZSON) requires agents to autonomously locate and approach unseen objects in unfamiliar environments and has emerged as a particularly challenging task within the domain of Embodied AI. Existing datasets for developing ZSON algorithms lack consideration of dynamic obstacles, object attribute diversity, and scene texts, thus exhibiting noticeable discrepancy from real-world situations. To address these issues, we propose a Dataset for Open-Vocabulary Zero-Shot Object Navigation in Dynamic Environments (DOZE) that comprises ten high-fidelity 3D scenes with over 18k tasks, aiming to mimic complex, dynamic real-world scenarios. Specifically, DOZE scenes feature multiple moving humanoid obstacles, a wide array of open-vocabulary objects, diverse distinct-attribute objects, and valuable textual hints. Besides, different from existing datasets that only provide collision checking between the agent and static obstacles, we enhance DOZE by integrating capabilities for detecting collisions between the agent and moving obstacles. This novel functionality enables evaluation of the agents' collision avoidance abilities in dynamic environments. We test four representative ZSON methods on DOZE, revealing substantial room for improvement in existing approaches concerning navigation efficiency, safety, and object recognition accuracy. Our dataset could be found at https://DOZE-Dataset.github.io/.
Dataset Overview
Example items in DOZE

(a) A static humanoid obstacle that obscures a basketball. (b) A dynamic humanoid obstacle walking on the floor. (c) An open-vocabulary object "Stegosaurus model". (d) Two distinct-spatial mugs: left next to a laptop, right next to an alarm clock. (e) Two distinct-appearance basketballs: left with orange color, right with gray color. (f) A hint whiteboard indicating the location of a tomato.
Examples of Partially Occluded Objects

In the DOZE dataset scenes, some objects are partially occluded. From left to right, four examples: the partially occluded objects are: rabbit, garbage can, tennis racket, and plunger.
Examples of Objects with Different Brands

In the DOZE dataset scenes, some appearance-attribute objects are with different brands. From left to right, two examples: two different brands of safes and two different brands of toliets.
Examples of Open-Vocabulary Objects

Some interesting examples of open-vocabulary objects in DOZE. First row, from left to right: a rabbit holding a sword, a cat on a skateboard, an astronaut model, a penguin wearing goggles, an outdoor tent. Second row, from left to right: a sheep with a hat, a wolf with a hat, a colorful peacock, a wizard, a monkey in a suit.
Dynamic goal object

We added an additional challenging task target to the DOZE dataset: a rolling basketball.
BibTeX
@article{ma2024doze,
title={DOZE: A Dataset for Open-Vocabulary Zero-Shot Object Navigation in Dynamic Environments},
author={Ma, Ji and Dai, Hongming and Mu, Yao and Wu, Pengying and Wang, Hao and Chi, Xiaowei and Fei, Yang and Zhang, Shanghang and Liu, Chang},
journal={arXiv preprint arXiv:2402.19007},
year={2024}
}Acknowledgement
This website is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.